Pour l’un de mes projets, j’ai des entrées en base de données dont la clé primaire est de type MEDIUMINT. En MySQL, c’est le type des entiers sur 24 bits, dont les valeurs peuvent donc aller de 1 à 16 777 215 en non signé.
Dans le cadre de ce projet, il est nécessaire de pouvoir accéder aux données depuis une interface web, donc en fournissant l’identifiant. Mais en même temps, des raisons de sécurité font qu’il n’est pas envisageable de rendre ces identifiants directement visibles par les utilisateurs. Il faut donc trouver un moyen de faire un hash unique de ces identifiants, qui soit injectif (on ne peut pas trouver l’identifiant initial à partir du hash).
Il existe un grand nombre d’algorithmes de hachage, certains qui sont cryptographiquement forts, d’autres qui se concentrent sur la rapidité d’exécution. Une répartition homogène des valeurs dans l’espace d’adressage est un objectif pour tous ces algorithmes.
Dans mon cas, il est important que l’algorithme utilisé ne génère pas de collisions avec des entiers sur 24 bits, pour s’assurer de l’unicité des hash générés. Pour le vérifier, j’ai fait un petit comparatif entre plusieurs méthodes de hachage. J’en ai choisies qui sont disponibles en PHP sur une distribution Ubuntu pas trop vieille : xxHash 32, xxHash 64, xxHash 128, CRC 32, CRC 32B, CRC 32C, Adler 32, FNV-1 32, FNV- 1a 32, FNV-1 64, FNV-1a 64, MD5, SHA-1, SHA-2 256, SHA-512, MurmurHash 3A, MurmurHash 3C, MurmurHash 3F.
Concernant la longueur des hash générés :
- 32 bits : xxHash 32, CRC 32, CRC 32B, CRC 32C, Adler32, FNV-1 32, FNV-1a 32, Murmur 3A
- 64 bits : xxHash 64, FNV-1 64, FNV-1a 64
- 128 bits : xxHash 128, MD5, Murmur 3C, Murmur 3F
- 160 bits : SHA-1
- 256 bits : SHA-256
- 512 bits : SHA-512
Je souhaite stocker des hash sur 32 bits, pour ne pas prendre trop d’espace supplémentaire en base de données. Pour les algorithmes qui dépassent 32 bits, il faut donc tronquer le résultat pour n’en garder que les 32 premiers bits.
Dans mon comparatif, j’ai mesuré le nombre de collisions générées par chaque algorithme, ainsi que leur rapidité d’exécution.
Temps de traitement
De manière générale le temps de hachage d’une seule entrée est infinitésimal, et ne fait pas de grande différence quand il s’agit de choisir un algorithme plutôt qu’un autre. Voici quand même le temps moyen (en secondes) que j’ai constaté pour la génération des 16M de hash :
- xxHash 32 : 1.056
- xxHash 64 : 1.337
- xxHash 128 : 1.419
- CRC 32 : 0.957
- CRC 32B : 0.934
- CRC 32C : 0.970
- Adler 32 : 0.882
- FNV-1 32 : 0.938
- FNV-1a 32 : 0.953
- FNV-1 64 : 0.987
- FNV-1a 64 : 1.062
- MD5 : 2.742
- SHA-1 : 3.2074
- SHA-256 : 6.197
- SHA-512 : 8.564
- MurmurHash 3A : 1.217
- MurmurHash 3C : 1.527
- MurmurHash 3F : 1.472
On peut voir que les algorithmes les plus lents sont ceux qui se veulent cryptographiquement forts, c’est-à-dire MD5, SHA1, SHA256 et SHA512 (même si MD5 et SHA1 ont été cassés, ce sont des algorithmes cryptographiques qui faisaient référence lors de leur conception).
La lenteur du SHA-512 est assez impressionnante. Il faut savoir que lorsque vous hachez des gros ensembles de données sur un processeur 64 bits, le SHA-512 est plus rapide que le SHA-256. Mais là, sur des nombres constitués de quelques chiffres, il est à la peine.
Première collision rencontrée
Comme mon besoin est de traiter des clés primaires auto-incrémentées, il est intéressant de mesurer la première valeur qui va générer une collision. Plus ce nombre est faible, moins l’algorithme est performant.
- xxHash 32 : 149 360
- xxHash 64 : 162 920
- xxHash 128 : 110 213
- CRC 32B : 14 740 600
- CRC 32C : 2 000 402
- Adler 32 : 201
- FNV-1 32 : 662 382
- FNV-1a 32 : 797 186
- FNV-1 64 : 2
- FNV-1a 64 : 492 320
- MD5 : 82 945
- SHA-1 : 40 686
- SHA-256 : 95 303
- SHA-512 : 93 656
- MurmurHash 3A : 87 960
- MurmurHash 3C : 78 585
On voit des résultats assez disparates. L’algorithme FNV-1 64 collisionne dès la seconde valeur ; cela vient du fait que les 32 premiers bits qu’il génère ne sont pas très bien distribués. Adler32 crée une collision à la deux cent-unième valeur, ce qui n’est pas une grande performance non plus.
Nombre de collisions totales
Pour commencer, voyons le nombre de collisions lorsqu’on utilise l’intégralité des valeurs possibles dans l’espace de 24 bits adressables (donc un total de 16 777 215 valeurs) :
- xxHash 32 : 18 170
- xxHash 64 : 32 934
- xxHash 128 : 32 270
- CRC 32 : 0
- CRC 32B : 10 240
- CRC 32C : 491 136
- Adler 32 : 16 763 413
- FNV-1 32 : 27 080
- FNV-1a 32 : 26 846
- FNV-1 64 : 15 099 653
- FNV-1a 64 : 26 741
- MD5 : 32 718
- SHA-1 : 32 487
- SHA-256 : 32 812
- SHA-512 : 32 553
- MurmurHash 3A : 32 908
- MurmurHash 3C : 32 757
- MurmurHash 3F : 0
On peut voir que l’algorithme Adler32 génère 99,91% de collisions, et 90% pour FNV-1 64 ! Je vais donc les écarter pour la suite du comparatif. Je vais sortir aussi le CRC32C, qui a près de 3% de collisions (c’est beaucoup moins que les deux précédents, mais ça reste énorme par rapport aux autres algorithmes).
On remarquera qu’un seul algorithme 32 bits ne génère absolument aucune collision : le CRC 32.
Un seul autre algorithme (128 bits) ne crée pas de collisions, le Murmur 3F.
On peut aussi remarquer que le SHA-512, malgré le fait qu’il soit le plus lent de tous, n’est pas plus efficace que les autres.
Nombre de collisions en fonction du nombre d’entrées
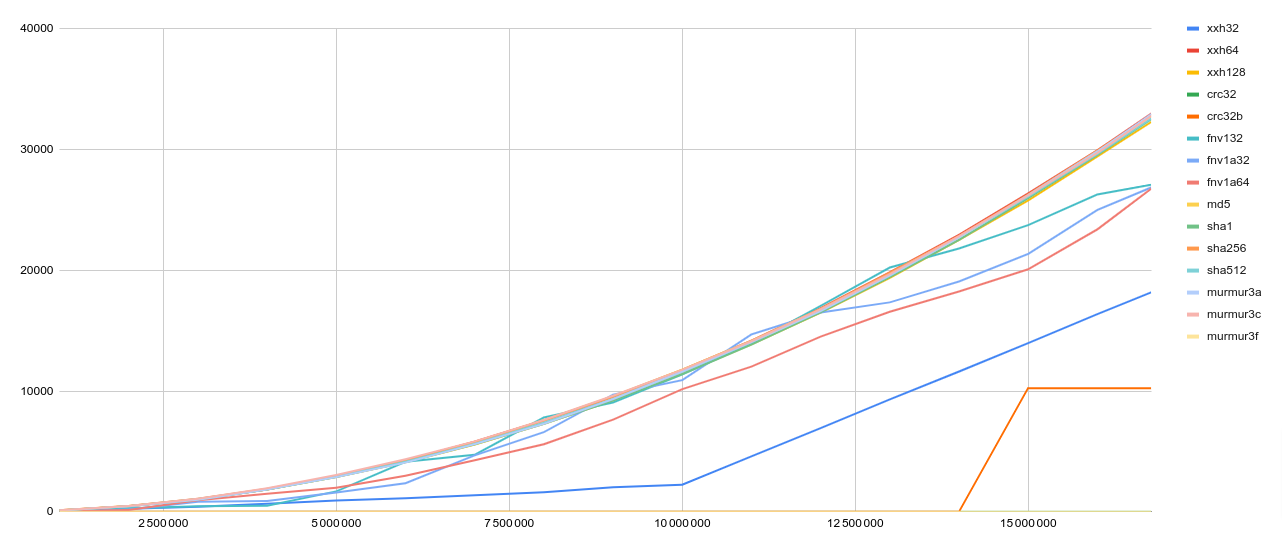
On peut voir que la plupart des algorithmes ont un nombre de collisions qui augmente de manière plus ou moins exponentielle.
xxHash 32 limite ses collisions jusqu’à environ dix millions d’entrées, puis le nombre augmente plus vite de manière linéaire.
CRC 32B ne génère aucune collision jusqu’à 14,5 millions d’entrées, puis reste stable à 10 240 collisions.
Conclusion
La conclusion est assez simple : je vais utiliser l’algorithme CRC32 « de base », qui ne génère aucune collision, qui est un tiers plus rapide que MurmurHash 3F.
Quelque part, je trouve ça assez amusant de voir que l’algorithme le plus simple et le plus ancien de ce comparatif reste le plus performant dans mon cas spécifique. Car il ne faut pas oublier que le CRC32 est utilisé dans un grand nombre de protocoles réseau (TCP/IP, Ethernet, Wifi…), dans les contrôles d’intégrité des disques durs et des CR-ROM, etc.
Comme quoi, l’implémentation de Gary S. Brown, écrite en 1986 et qui se retrouve encore aujourd’hui dans tous les systèmes de la planète (tapez « gary s. brown crc32.c » dans Google et vous verrez des références comme Apple, Android, Java, Fedora Linux, FreeBSD, OpenWRT, VirtualBox, OpenSSH, Cisco…), était de très bonne qualité.
Pour aller plus loin : 28 bits de données
J’ai voulu tenter l’expérience avec des données réparties sur 28 bits au lieu de 24. Cela donne des valeurs qui peuvent aller jusqu’à 268 435 454. Est-il possible d’utiliser un hash sur 32 bits pour adresser ces valeurs ?
J’ai évidemment restreint ce test aux algorithmes CRC32 et Murmur3F. Les résultats sont assez étonnants :
- CRC32 génère 4 100 224 collisions
- Murmur3F ne génère aucune collision. Zéro. C’est impressionnant.
CRC32 commence à avoir des collisions à partir de la valeur 40 040 200, ce qui est bien plus performant que tous les autres algorithmes testés précédemment (sauf le Murmur 3F). Mais c’est loin d’être suffisant quand on veut manipuler 28 bits de données.
